
1. 序列对象
Python标准库用C语言实现了丰富的序列类型,从底层实现的角度来分类,可以分为容器序列和扁平序列.列举如下.
容器序列
list、tuple和collections.deque这些序列能存放异构(不同类型的)数据.本质上存储的内容是引用,关于引用,可以看python数据模型部分的相关介绍.扁平序列
str、bytes、bytearray、memoryview,array.array以及准标准库numpy.array.这类序列只能容纳同构(同一种类型的)数据.
容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用.换句话说,扁平序列其实是一段连续的内存空间. 由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型. 序列类型还能按照能否被修改来分类:
可变序列
MutableSequencelist、bytearray、array.array、collections.deque和memoryview.不可变序列
Sequencetuple、str、bytes和numpy.ndarray
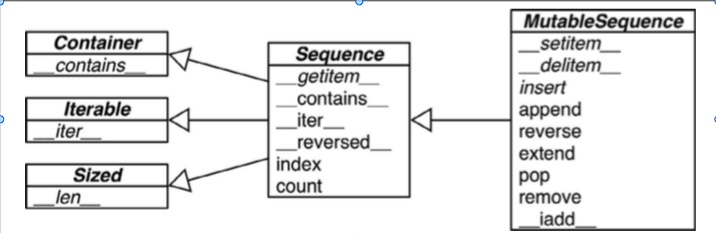
下图显示了可变序列和不可变序列的差异,同时也能看出前者从后者那里继承了一些方法.虽然内置的序列类型并不是直接从Sequence和 MutableSequence这两个抽象基类继承而来的.但是了解这些基类可以帮助我们总结出那些完整的序列类型包含了哪些功能:
扁平序列内置类型相关的操作可以看文本文件与字节序相关的内容.
另一个准标准库numpy提供了一套更加高效的同构定长数组工具,它属于向量计算部分的范畴,本节不做介绍.
本章需要的先验知识包括:
1.1. 序列操作
python是高度一致性理念下的产物,它的序列很能够体现这一特点.不同类型的序列虽然特性不同,但都满足一致的接口协议,因此有着一致的行为.了解序列操作只要了解这些接口协议即可
1.1.1. 只要满足Iterable,我们的序列就可以使用for循环遍历
for i in (1,2,3,4,5): print(i) 1 2 3 4 5 1.1.2. 只要满足Sized我们的序列就可以使用len内置方法求取序列的长度
len((1,2,3,4,5)) 5 1.1.3. 只要满足Container我们的序列就可以使用in语句判断元素是否在序列中
1 in (1,2,3,4,5) True - 只要满足
Sequence我们就可以使用切片操作,翻转序列,使用count方法和index方法
1.1.4. 切片操作
python用[]来取值和切片,它对应的魔术方法是__getitem__.
python内置类型有一套非常便捷的切片逻辑
取位
比如[1]代表取第一位的值(序列中为第2个元素).[-1]代表最后一个元素
(1,2,3,4,5)[0] 1 切片
而当[]中有两个被
:分割开得数时就成了切片,比如[2:4]代表取从第2位到第3位的元素组成一个与原来序列相同类型的新序列,:分隔的两边可以没有指定,意味头尾元素,后一位可以为负数,意为倒着数
(1,2,3,4,5)[:-2] for i in (1,2,3,4,5): print(i) 0按步长切片
而当[]中有三个被
:分割开得数时就成了切片,比如[0:4:2]代表每2个元素从第0位到第3位取出组成一个与原来序列相同类型的新序列,第二位可以为负数,意为倒着数,最后一位可以为负数,意味从尾到头获取.
for i in (1,2,3,4,5): print(i) 1for i in (1,2,3,4,5): print(i) 21.1.5. count计算元素在序列中出现的次数
for i in (1,2,3,4,5): print(i) 3for i in (1,2,3,4,5): print(i) 41.1.6. reversed翻转序列
翻转序列操作返回的是一个可迭代对象并非序列
for i in (1,2,3,4,5): print(i) 5for i in (1,2,3,4,5): print(i) 61.1.7. 只要满足MutableSequence我们就可以使用insert,append,pop,extend,remove操作
list.append(obj) 在列表末尾添加新的对象
list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list.insert(index, obj) 将对象插入列表
list.pop(obj=list[-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.remove(obj) 移除列表中某个值的第一个匹配项
1.1.8. 对序列使用+,*,+=,*=
Python的内置序列类型会默认支持+ 和* 操作的.+和*分别对应特殊方法__add__和__mul__
通常+号两侧的序列由相同类型的数据所构成,在拼接的过程中,两个被操作的序列都不会被修改,Python 会新建一个包含同样类型数据的序列来作为拼接的结果.
如果想要把一个序列复制几份然后再拼接起来,更快捷的做法是把这个序列乘以一个整数.同样,这个操作会产生一个新序列:
+和*都遵循这个规律,不修改原有的操作对象,而是构建一个全新的序列。
for i in (1,2,3,4,5): print(i) 7for i in (1,2,3,4,5): print(i) 8for i in (1,2,3,4,5): print(i) 91 2 3 4 5 01 2 3 4 5 1增量赋值运算符+= 和*= 的表现取决于它们的第一个操作对象.简单起见,我们把讨论集中在增量加法(+=)上,但是这些概念对*=和其他增量运算符来说都是一样的.+= 背后的特殊方法是__iadd__(用于"就地加法").但是如果一个类没有实现这个方法的话,Python 会退一步调用__add__.考虑下面这个简单的表达式:
1 2 3 4 5 2如果a 实现了__iadd__ 方法,就会调用这个方法.同时对可变序列(例如list、bytearray 和array.array)来说,a会就地改动,就像调用了a.extend(b)一样.但是如果a没有实现__iadd__的话,a += b这个表达式的效果就变得跟a = a + b 一样了:
- 首先计算
a + b,得到一个新的对象 - 然后赋值给
a
也就是说,在这个表达式中,变量名会不会被关联到新的对象,完全取决于这个类型有没有实现__iadd__这个方法.
总体来讲,可变序列一般都实现了__iadd__ 方法,因此+=是就地加法.而不可变序列根本就不支持这个操作,对这个方法的实现也就无从谈起. 上面所说的这些关于+= 的概念也适用于*=,不同的是,后者相对应的是__imul__.
1.2. 列表list
最重要也最基础的序列类型应该就是列表(list)了.list是一个可变序列,并且能同时存放不同类型的元素.本质上list就是类似c++中vector的数据结构.因此它的效率并不高.list是单向序列,因此使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了. list是线性存储,数据量大的时候,插入和删除效率很低.
列表的构造函数是list(*items),python中也可以使用[]来构造
1.2.1. 列表推导
所谓列表解析就是在列表中写入代码段,吧代码段生成的结果放入列表中.列表解析除了支持使用for循环构建列表,也支持使用if筛选数据
1 2 3 4 5 31 2 3 4 5 41 2 3 4 5 51 2 3 4 5 61.3. 双向队列deque
collections.deque是一个是一个线程安全,高效实现插入和删除操作的双向列表,适合用于队列和栈
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素.
1 2 3 4 5 71 2 3 4 5 81 2 3 4 5 9len((1,2,3,4,5)) 0len((1,2,3,4,5)) 1len((1,2,3,4,5)) 2如果想要有一种数据类型来存放"最近用到的几个元素",deque 也是一个很好的选择.这是因为在新建一个双向队列的时候,你可以指定这个队列的大小,如果这个队列满员了,还可以从反向端删除过期的元素,然后在尾端添加新的元素.
双向队列也付出了一些代价,从队列中间删除元素的操作会慢一些,因为它只对在头尾的操作进行了优化
len((1,2,3,4,5)) 3len((1,2,3,4,5)) 4len((1,2,3,4,5)) 5len((1,2,3,4,5)) 6len((1,2,3,4,5)) 4len((1,2,3,4,5)) 5len((1,2,3,4,5)) 9len((1,2,3,4,5)) 45 15 2len((1,2,3,4,5)) 45 45 5len((1,2,3,4,5)) 45 7除了deque之外,还有些其他的Python标准库也有对队列的实现.
queue
提供了同步(线程安全)类Queue、LifoQueue和PriorityQueue,不同的线程可以利用这些数据类型来交换信息.这三个类的构造方法都有一个可选参数maxsize,它接收正整数作为输入值,用来限定队列的大小.但是在满员的时候,这些类不会扔掉旧的元素来腾出位置.相反,如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而腾出了位置.这一特性让这些类很适合用来控制活跃线程的数量.
multiprocessing.Queue
这个包实现了自己的Queue,它跟queue.Queue类似,是设计给进程间通信用的.同时还有一个专门的multiprocessing.JoinableQueue类型,可以让任务管理变得更方便.
asyncio.Queue
Python 3.4新提供的包,里面有Queue、LifoQueue、PriorityQueue和JoinableQueue,这些类受到queue和multiprocessing模块的影响,但是为异步编程里的任务管理提供了专门的便利.
以上的队列基本都是为并行计算设计的,会在流程控制部分细讲
heapq堆
跟上面三个模块不同的是,heapq 没有队列类,而是提供了heappush 和heappop 方法,让用户可以把可变序列当作堆队列或者优先队列来使用.
5 85 91 in (1,2,3,4,5) 01 in (1,2,3,4,5) 11 in (1,2,3,4,5) 21 in (1,2,3,4,5) 31 in (1,2,3,4,5) 41 in (1,2,3,4,5) 51 in (1,2,3,4,5) 61 in (1,2,3,4,5) 71 in (1,2,3,4,5) 61 in (1,2,3,4,5) 91.4. 元组tuple
元组是不可变序列,构造函数为tuple(seq),也可以使用(,)来快速构建.
元组如果保存元素都不是容器,那么元组就是真正的不可变的,否则还是会根据内部元素的改变而改变.
1.5. 具名元组
collections.namedtuple是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类——这个带名字的类对调试程序有很大帮助. 用namedtuple构建的类的实例所消耗的内存跟元组是一样的,因为字段名都被存在对应的类里面.这个实例跟普通的对象实例比起来也要小一些,因为Python不会用__dict__来存放这些实例的属性.
True 0True 1True 2True 3True 4True 5True 6除了从普通元组那里继承来的属性之外,具名元组还有一些自己专有的属性.下面的例子展示了几个最有用的:
_fields类属性_fields属性是一个包含这个类所有字段名称的元组.
True 7True 8类方法
_make(iterable)_make()通过接受一个可迭代对象来生成这个类的一个实例
True 9(1,2,3,4,5)[0] 0(1,2,3,4,5)[0] 1实例方法
_asdict()_asdict()把具名元组以collections.OrderedDict的形式返回,我们可以利用它来把元组里的信息友好地呈现出来
(1,2,3,4,5)[0] 2(1,2,3,4,5)[0] 3(1,2,3,4,5)[0] 4(1,2,3,4,5)[0] 51.5.1. 带有类型标注的具名元组
使用collections.namedtuple无法使用typing做类型标注,这在大型项目中不利于团队合作.
3.5中加入的标准库typing提供了一种可以带类型标注的具名元组typing.NamedTuple,它可以实现对具名元组中字段的类型标注:
(1,2,3,4,5)[0] 6(1,2,3,4,5)[0] 7(1,2,3,4,5)[0] 8(1,2,3,4,5)[0] 9


")




还没有评论,来说两句吧...