

10月26日,北京站源创会,聊聊高性能计算与大模型推理


近日 Apache StreamPark(Incubating) PMC 正式发布了 Apache StreamPark 2.1.5 版本,该版本是 2.1 系列版本 的第 5 个小版本,也是最后一个版本,社区已决定下个发布版本是 2.2。在本次发布,进一步优化易用性,支持了 Apache Flink 1.20,访问 Filnk UI 支持代理,重构了 OpenAPI 的接口访问,修复一些历史 BUG,该版本历经了 5 个月,共有 20 余位开发者参与开发和测试,感谢开发者的贡献。用
Github: https://github.com/apache/streampark
官 网: https://streampark.apache.org/download
新特性解读
1. 跳转 Flink UI 支持代理
在 StreamPark 的之前的版本中,跳转 Flink WebUI 是直接在用户浏览器中打开 Flink WebUI,由于部署 StreamPark 的机器和作业的 Flink WebUI 很多时候不在同一台机器, 要确保能正常访问,需要做很多前置的工作,如:在 Flink On YARN 部署模式下,需要用户本地机器能正常访问所有的 Hadoop 节点,一般会将 Hadoop 节点列表配置到用户本地的 Host 里,并且允许网络访问这些 Hadoop 节点;在 Flink On Kubernetes 模式下 StreamPark 之前提供的方案是通过配置 Ingress 来解决,这种方式不但需要专业知识,且配置起来也比较麻烦,有一定的使用门槛。
在本次 2.1.5 中,StreamPark 已经实现代理访问 Flink WebUI,无需用户做任何配置,直接打开链接即可,大大提升使用体验。
2.开放 Open API
越来越多的用户使用 StreamPark 作为流计算平台的底座来构建内部的大数据平台。因此社区经常收到关于第三方调用 API 的相关问题,在本次的版本中,我们重新实现了 Open API,在保证安全的同时,更好的支持 Open API。
使用步骤:
1. 点击进入作业详情,在 Rest Api 中有两个按钮:App Start 和 App Cancel
2. 点击 App Start 或者 App Cancel 会弹窗显示接口详情:列出接口 URL 和请求的参数。
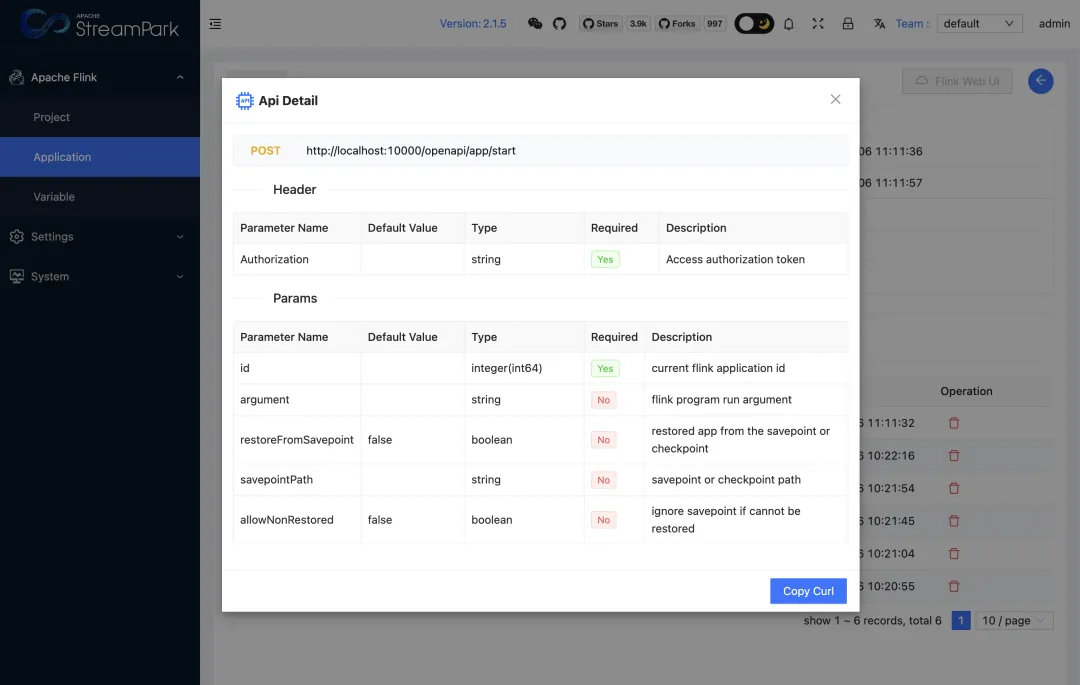
3. 点击接口详情下的 Copy Curl,会复制该接口的请求参数,注:这里的 Curl 只是个请求示例,可以简单直观的描述接口的各项参数,你可以根据这个 Crul 请求,将该请求转换成需要的相关语言的请求方式即可。
示例 Curl:
curl -X POST 'http://localhost:10000/openapi/app/start' \ -H 'Authorization: 69qMW7reOXhrAh29L...' \ -H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' \ --data-urlencode 'argument=' \ --data-urlencode 'savepointPath=' \ --data-urlencode 'allowNonRestored=false' \ --data-urlencode 'id=100000' \ --data-urlencode 'restoreFromSavepoint=false' 4. 如果还未给当前登录用户添加 Token 则会提示:请联系管理员添加 Token。
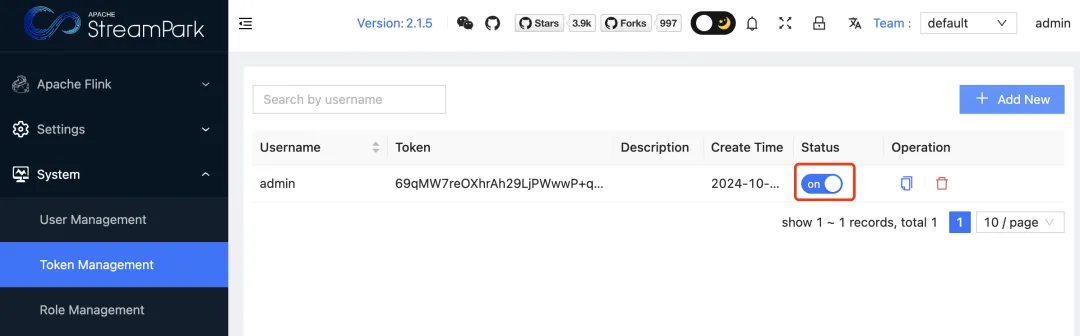
5. 如未添加 Token 则需要管理员进入到系统设置菜单,找到:令牌管理(Token Management),给该用户添加 Token。
6. 再次打开接口详情页面,复制该 App Start 的 Curl,并在命令行下执行该请求,如果没有其他意外会看到该作用已正常运行起来。
注意:
请求 Open API 需要Token,该 Token不要使用系统前后端请求 Header 里的 Authorization,虽然也能正常请求,但是前后端接口请求里的 Authorization 有过期时间,一旦 Session 过期,就会自动失效。这里一定要使用 Token 管理中的 Token,该 Token 管理员可以很轻松的管理,如:某个用户的 Token 被回收和删除,则该用户之前的 Open API 再次请求就会失败。
3. Flink 配置支持变量
在 StreamPark 之前的版本中,配置 Flink 相关参数,一直是一个固定的参数,如将: state.checkpoints.dir 和 state.savepoints.dir 设置为:hdfs://flink/savepoint,该路径被读取后会生效,但是带来一个问题:会将所有作业的 savepoint 和 checkpoint 都放到同一个路径下,用户期望理想的方式是每个作业有一个专属的路径,这样就避免作业状态路径混乱的问题。因此在该版本中,我们支持了通过变量的方式来配置,目前支持两个变量: ${jobId} 和 ${jobName}, 只需要在 flink-conf.yaml 或 config.yaml 里配置变量即可,在 StreamPark 启动作业时会自动将这些变量替换为作业真实的 jobId 和 jobName,具体配置如下:
# Execution checkpointing related parameters... state.checkpoints.dir: hdfs:///streampark/checkpoints/${jobId} state.savepoints.dir: hdfs:///streampark/savepoints/${jobName} # state.backend.incremental: false 4. 支持 Apache Flink 1.20
本次支持了 Flink 1.20,在使用上非常的简单,用户只需要添加一个 Flink 1.20 的环境即可为作业自由地选择 Flink 版本。并且 Apache StreamPark 适配了更多发行版的 Flink,如 CDH 版本的 Flink、华为云、腾讯云 Flink 等。
5. 一键安装脚本
Apache StreamPark 一直非常重视易用性,我们一直在思考如何进一步降低用户的部署负担,让从未使用过 StreamPark 的新用户不用去翻阅文档,只需要简单几步骤就能快速体验,因此,本次我们特别新增了一键安装使用脚本,只需要执行一个命令即可完成安装,登录到系统点击默认的示例作业就能运行起来。
curl -L https://streampark.apache.org/quickstart.sh | sh 其他更新
其他改进和更新
-
修复了 Flink 1.20 On YARN PerJob 模式下 API 不兼容导致启动作业失败的 BUG。
-
改进项目模块,新增根据 Git 的 Tag 来 Clone 项目。
-
修复了在 JDK 8+ 某些版本下 Flink On YARN 初始化 Hadoop 失败的 BUG。
-
改进并验证了 StramPark 在不同版本 JDK 下的兼容性, 完整适配了所有的 JDK 版本。
-
修复了 Flink On YARN 被 Kill 的情况下,作业列表页面状态未显示的 BUG。
-
修复了一些 OpenAPI 认证和鉴权方面的 BUG。
-
修复 Token 令牌失效的 BUG。
-
改进页面搜索栏样式,统一弹窗表格样式,使前端风格更加自然统一。
-
重构了部分页面(首页,项目,Flink home, Flink env),页面核心部分更突出,整体风格更统一成熟。
-
修复某些情况下 Checkpoint 不记录的 BUG 。
-
修复 Flink On Kubernetes Application 模式作业停止时未清理 HA 文件,导致下次启动新作业时启动两个相同作业的问题。
-
修复获取最新检查点未统计 FAILED 的 BUG。
-
为 Kubernetes 模式部署的 POD 添加 JobID 标签,更方便与其他平台如 Prometheus 集成。
离支持 Spark 还远吗?
StreamPark 对 Apache Spark 的支持能力,目前研发测试进度已进入尾声,计划在下个大版本 2.2 中推出,同时支持 Apache Spark 2.x/3.x 版本,支持 On YARN/Kubernetes 部署模式,支持 Spark Jar/SQL/Shell 作业,使用体验和操作流程和 Apache Flink 作业一致,欢迎届时使用体验。
感谢贡献者
StreamPark 开源社区的发展,离不开广大用户群体的积极反馈和宣传布道,更离不开贡献者们的无私贡献,感谢对此版本做出贡献的每一位贡献者。特别感谢本次的 Release Manager @张超[1],阿超老师在发版过程中积极地跟踪问题和推进进度,出色地完成了此次发版工作。感谢阿超老师为社区做出的贡献,也欢迎其他 PPMC member 和 Committer 在后续的发版中担任 Release Manager,帮助社区更快捷、高质量地完成发版。
🧐 什么是 StreamPark
Apache StreamPark 是一个流处理应用程序开发管理框架。旨在轻松构建和管理流处理应用程序,提供使用 Apache Flink 和 Apache Spark 编写流处理应用程序的开发框架和一站式流计算平台,核心能力包括但不限于应用开发、调试、交互查询、部署、运维、实时数仓等。目前已有腾讯、百度、联通、天翼云、自如、马蜂窝、同程数科、长安汽车、天眼查等众多公司在生产环境使用、并且获得了多项业内荣誉,是近年来成长较快的开源项目。
🫵 加入我们
Apache StreamPark 加入 ASF 孵化器以来,社区一直以来都以用心做好一个项目为原则,高度关注项目质量和用户的落地使用,努力建设发展社区,认真学习和遵循「The Apache Way」,目前项目趋于成熟,已临近毕业。诚挚欢迎更多的贡献者参与到社区建设中来,和我们一道携手共建,共同见证项目的毕业。
💻 项目地址:https://github.com/apache/streampark
🧐 提交问题和建议:https://github.com/apache/streampark/issues
🥁 贡献代码:https://github.com/apache/streampark/pulls
📮 Proposal:https://cwiki.apache.org/confluence/display/INCUBATOR/StreamPark+Proposal
📧 订阅社区开发邮件列表:[email protected] [2]
💁♀️社区沟通:

参考资料
[1] https://github.com/VampireAchao
[2] mailto:[email protected]
祝大家安装、升级顺利~~


")





还没有评论,来说两句吧...