

阅读《2024 中国开源开发者报告》赢大奖,扫码申请享特权


简体中文 | English | 帮助文档
RAG 从未如此简单
minRAG是从零开始的RAG系统,追求极致的简单和强大,不超过1万行代码,无需安装,双击启动.支持OpenAI、Gitee AI、百度千帆、腾讯云LKE、阿里云百炼、字节火山引擎等AI平台.
使用FTS5实现BM25全文检索,使用Vec实现向量检索,实现了 MarkdownConverter、DocumentSplitter、OpenAIDocumentEmbedder、SQLiteVecDocumentStore、OpenAITextEmbedder、VecEmbeddingRetriever、FtsKeywordRetriever、DocumentChunkReranker、PromptBuilder、OpenAIChatMemory、OpenAIChatGenerator、ChatMessageLogStore、Pipeline等组件,支持流水线设置和扩展.
支持的AI平台
因为 reranker 没有统一标准,组件参数中base_url要填写完整的路径
OpenAI
minRAG实现了OpenAI的标准规范,所有兼容OpenAI的平台都可以使用.
Gitee AI(默认)
AI平台默认是 Gitee AI,Gitee AI每天100次免费调用
- 注册或设置页面的AI平台
base_url填写 https://ai.gitee.com/v1 - 注册或设置页面的AI平台
api_key填写 免费或者付费的token OpenAITextEmbedder默认使用bge-m3模型GiteeDocumentChunkReranker组件参数{"base_url":"https://ai.gitee.com/api/serverless/bge-reranker-v2-m3/rerank","model":"bge-reranker-v2-m3"}OpenAIChatGenerator建议使用DeepSeek-V3模型
腾讯云LKE知识引擎
- 注册或设置页面的AI平台
base_url填写SecretId,或在组件参数配置{"SecretId":"xxx"} - 注册或设置页面的AI平台
api_key填写SecretKey,或在组件参数配置{"SecretKey":"xxx"} LKETextEmbedder和LKEDocumentEmbedder默认使用lke-text-embedding-v1模型LKEDocumentChunkReranker默认使用lke-reranker-base模型OpenAIChatGenerator使用OpenAI SDK方式接入,组件参数配置{"base_url":"https://api.lkeap.cloud.tencent.com/v1","api_key":"xxx","model":"deepseek-v3"}- 记得修改流水线中的组件
百度千帆
- 注册或设置页面的AI平台
base_url填写 https://qianfan.baidubce.com/v2 - 注册或设置页面的AI平台
api_key填写 永久有效API Key OpenAITextEmbedder和OpenAIDocumentEmbedder默认使用bge-large-zh模型,1024维度DocumentChunkReranker组件参数配置{"base_url":"https://qianfan.baidubce.com/v2/rerankers","model":"bce-reranker-base","top_n":5,"score":0.1}OpenAIChatGenerator建议使用deepseek-v3模型- 记得修改流水线中的组件
阿里云百炼
- 注册或设置页面的AI平台
base_url填写 https://dashscope.aliyuncs.com/compatible-mode/v1 - 注册或设置页面的AI平台
api_key填写 申请的API KEY OpenAITextEmbedder和OpenAIDocumentEmbedder默认使用text-embedding-v3模型,1024维度BaiLianDocumentChunkReranker组件参数配置{"base_url":"https://dashscope.aliyuncs.com/api/v1/services/rerank/text-rerank/text-rerank","model":"gte-rerank","top_n":5,"score":0.1}OpenAIChatGenerator建议使用deepseek-v3模型- 记得修改流水线中的组件
字节火山引擎
- 注册或设置页面的AI平台
base_url填写 https://ark.cn-beijing.volces.com/api/v3 - 注册或设置页面的AI平台
api_key填写 申请的API KEY OpenAITextEmbedder和OpenAIDocumentEmbedder建议使用doubao-embedding模型,兼容1024维度DocumentChunkReranker火山引擎暂时没有Reranker模型,建议使用其他平台的Reranker模型或者去掉OpenAIChatGenerator建议使用deepseek-v3模型- 记得修改流水线中的组件
tika集成
默认minRAG只支持markdown和text等文本格式,可以使用TikaConverter组件调用tika服务解析文档内容,TikaConverter组件配置示例:
{ "tikaURL": "http://localhost:9998/tika", "defaultHeaders": { "Content-Type": "application/octet-stream" } } 启动 tika 的命令如下:
## tika 3.x 依赖 jdk11+ java -jar tika-server-standard-3.1.0.jar --host=0.0.0.0 --port=9998 ## 不输出日志 #nohup java -jar tika-server-standard-3.1.0.jar --host=0.0.0.0 --port=9998 >/dev/null 2>&1 & 或者下载tika-windows start.bat启动tika.
注意修改indexPipeline流水线的参数,把原来的MarkdownConverter替换为TikaConverter:
{ "start": "TikaConverter", "process": { "TikaConverter": "DocumentSplitter", "DocumentSplitter": "OpenAIDocumentEmbedder", "OpenAIDocumentEmbedder": "SQLiteVecDocumentStore" } } 界面预览
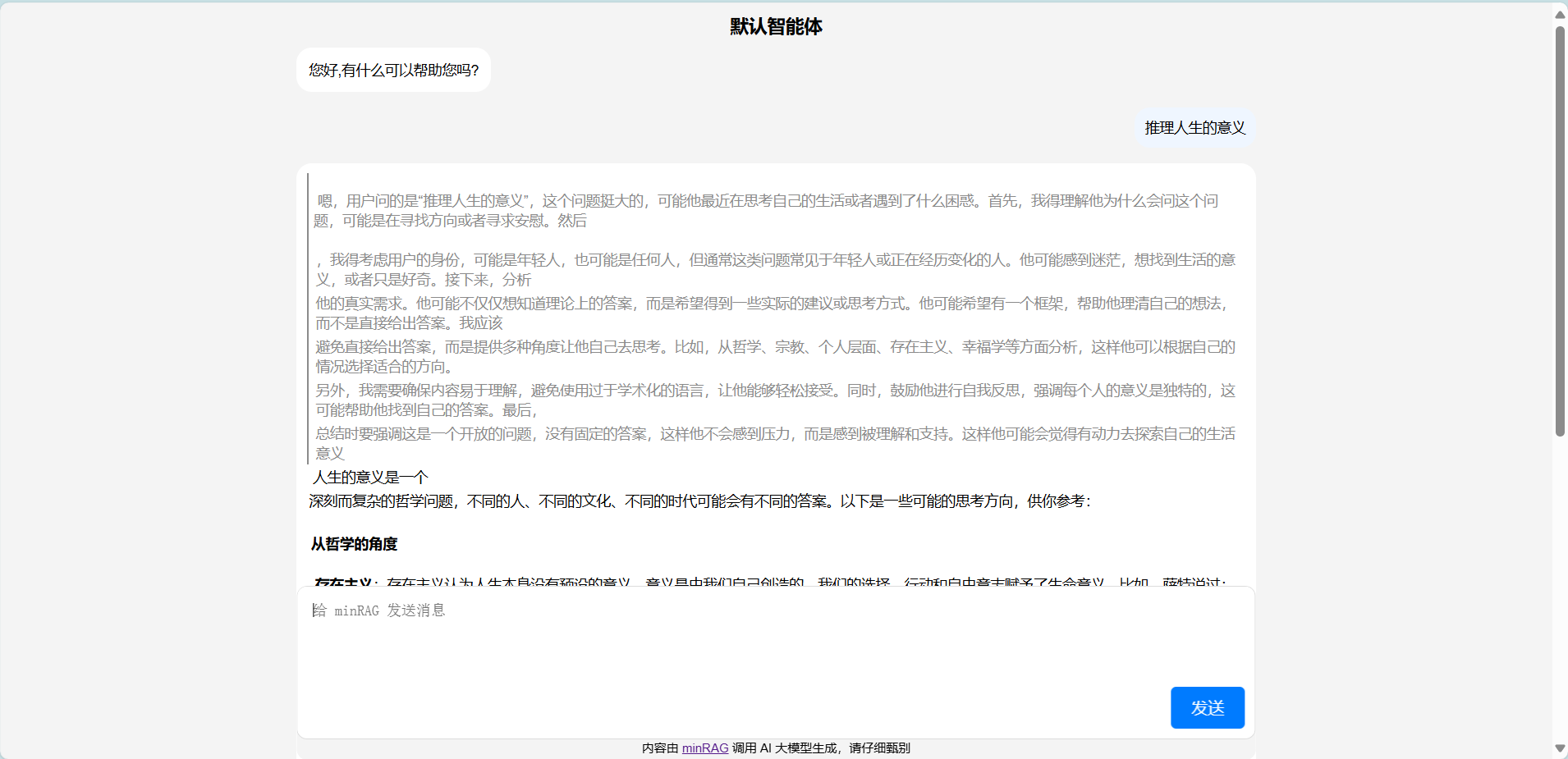
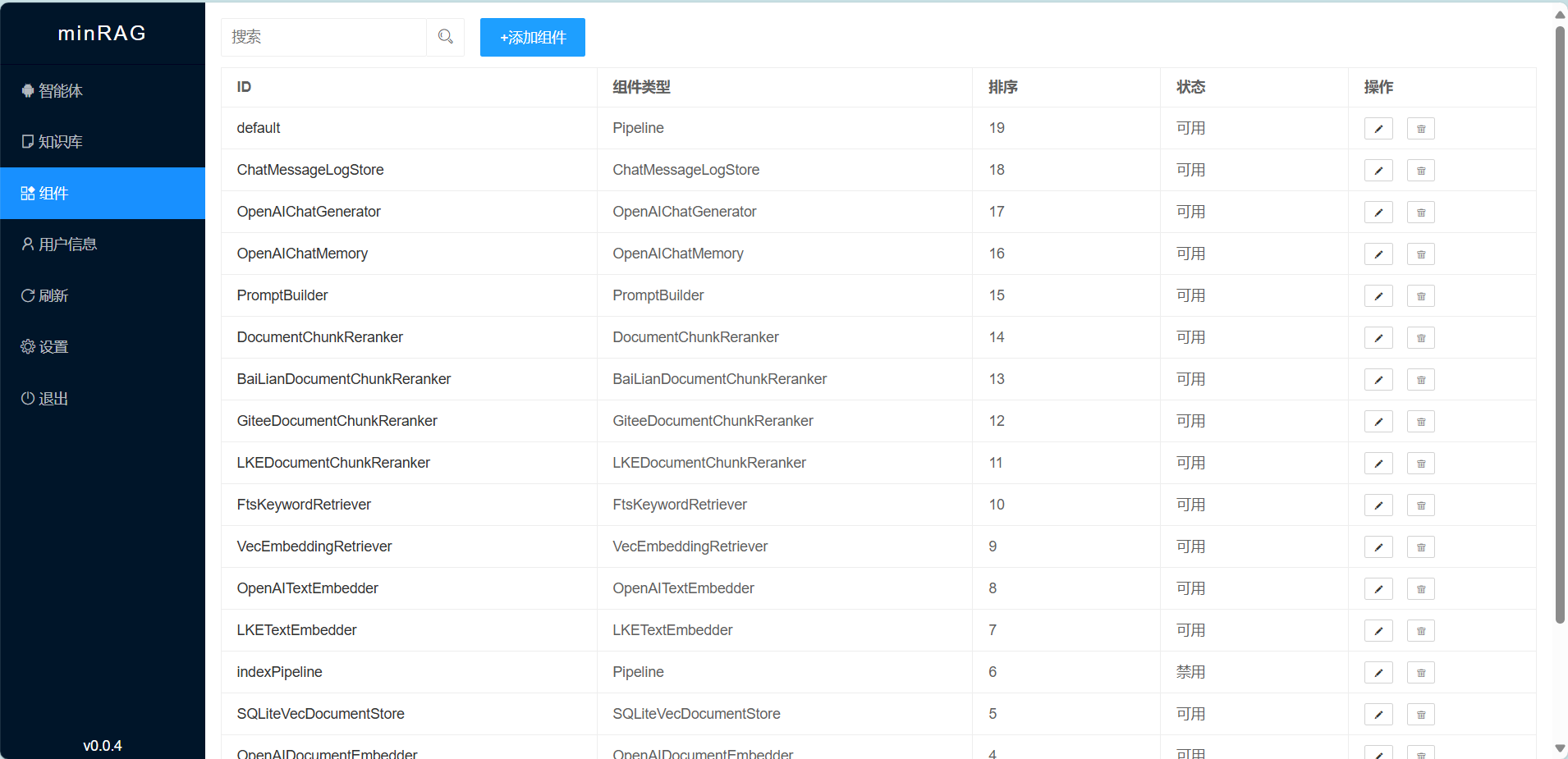
更新:
- 增加TikaConverter组件,支持tika文档解析
- 增加文档说明
- 修复删除按钮功能
-
完善注释,文档


更新")




还没有评论,来说两句吧...