

阅读《2024 中国开源开发者报告》赢大奖,扫码申请享特权

x-easypdf v3.3.0 发布,拥有 AI 加持的 pdf 框架

x-easypdf 是一个 java 语言简化处理 pdf 的框架,包含 fop 模块与 pdfbox 模块,fop 模块以创建功能为主,基于 xsl-fo 模板生成 pdf 文档,以数据源的方式进行模板渲染;pdfbox 模块以编辑功能为主,对标准的 pdfbox 进行扩展,添加了成吨的功能。
本次更新内容如下:
新特性:
- 【pdfbox】新增 jpeg2000 格式图像支持
- 【pdfbox】新增大模型解析文档的支持
- 【pdfbox】新增开源中国(gitee)AI 解析器
- 【pdfbox】新增智谱(glm)AI 解析器
- 【pdfbox】新增腾讯(hunyuan)AI 解析器
- 【pdfbox】新增阿里(qwen)AI 解析器
- 【pdfbox】新增深度求索(deepseek)AI 解析器
- 【pdfbox】新增字节跳动(doubao)AI 解析器
- 【pdfbox】新增昆仑万维(tiangong)AI 解析器
- 【pdfbox】新增月之暗面(kimi)AI 解析器
- 【pdfbox】新增讯飞(spark)AI 解析器
- 【pdfbox】新增线性化支持
- 【pdfbox】新增 office 文件转换 pdf 的支持(依赖 office 服务)
- 【pdfbox】新增 word 转换器
- 【pdfbox】新增 excel 转换器
- 【pdfbox】新增 ppt 转换器
- 【pdfbox】新增 html 转换器
- 【pdfbox】新增 rtf 转换器
- 【pdfbox】新增附件处理器
- 【pdfbox】新增加载 awt 字体的支持
- 【fop】新增条形码无白边配置
- 【fop】新增设置条形码缓存的方法
- 【fop】新增权限配置
- 【fop】新增从资源路径加载 awt 字体的支持
原有变更:
maven 坐标变更,原 groupId “org.dromara.x-easypdf” 变更为 “org.dromara”
问题修复:
- 【pdfbox 模块】修复表格组件单元格添加多组件换行错误问题
- 【pdfbox 模块】修复表格重叠问题
- 【pdfbox 模块】修复空文本错误问题
AI 解析功能演示:
原文档:
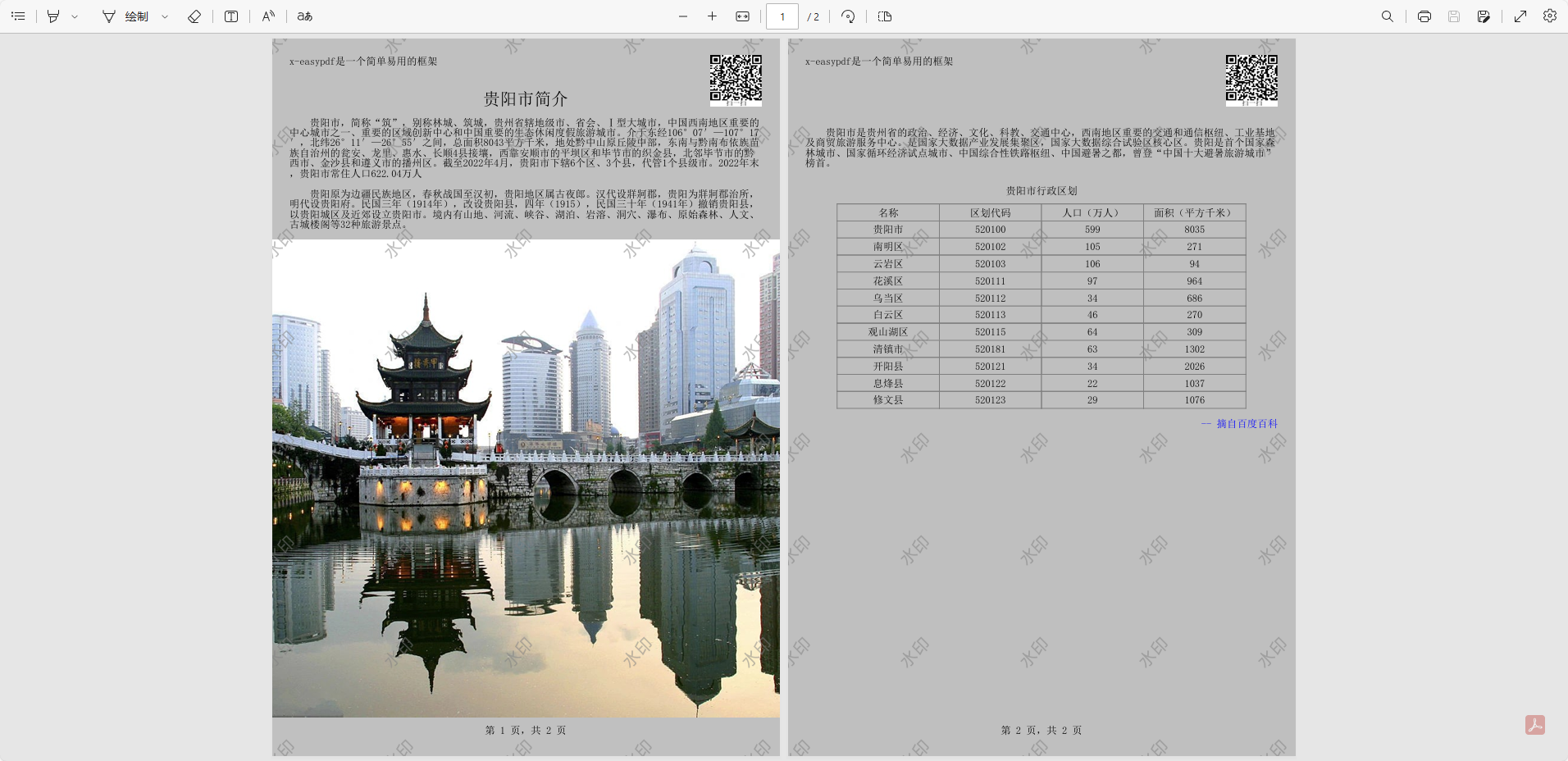
解析图像示例:
/** * 页面图像测试 */ @Test public void parseImageWithPageTest() { String ak = System.getenv("ak"); String sk = System.getenv("sk"); Document document = PdfHandler.getDocumentHandler().load("E:\\\\\\\\PDF\\\\\\\\pdfbox\\\\\\\\allTest.pdf"); TencentAIParser parser = PdfHandler.getDocumentAIParser(document).getTencentAI(ak, sk, false); AIParseInfo info = parser.parseImageWithPage("根据“这是一张XXX地点XXX的图片”的格式描述图片展示的内容,说出具体的城市,使用中文回答", 0, 1); log.info("返回内容:\\\\n" + info.getResult()); document.close(); } 返回内容:

解析文本示例:
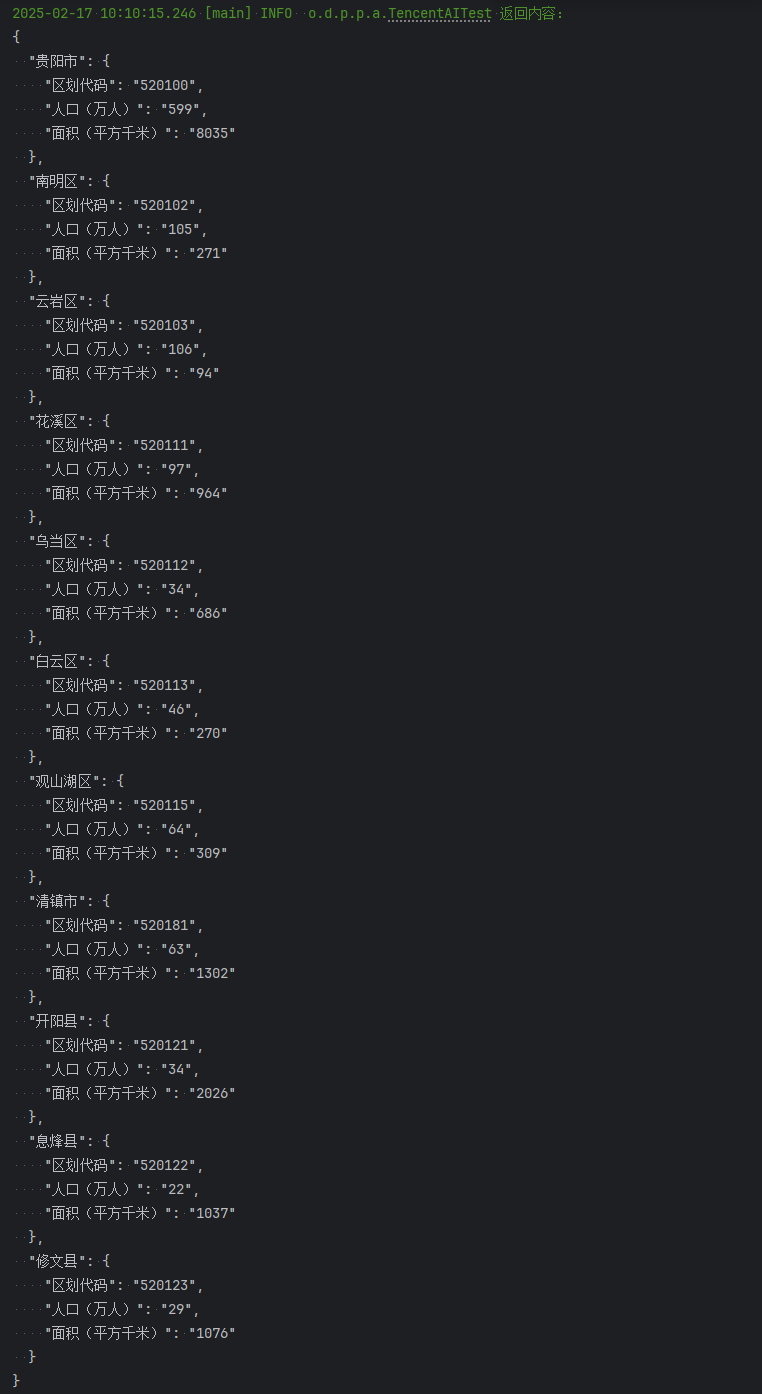
/** * 文档文本测试 */ @Test public void parseTextWithDocumentTest() { String ak = System.getenv("ak"); String sk = System.getenv("sk"); Document document = PdfHandler.getDocumentHandler().load("E:\\\\PDF\\\\pdfbox\\\\allTest.pdf"); TencentAIParser parser = PdfHandler.getDocumentAIParser(document).getTencentAI(ak, sk, true); AIParseInfo info = parser.parseTextWithDocument("提取表格内容,以json格式返回"); log.info("返回内容:\\n" + info.getResult()); document.close(); } 返回内容:








还没有评论,来说两句吧...