

阅读《2024 中国开源开发者报告》赢大奖,扫码申请享特权

微软近日发布了 OmniParser V2 版本,该工具能够将各种 LLM 变成可操控计算机的 AI Agent。
图形用户界面(GUI)自动化需要能够理解并交互于用户屏幕的 Agent。然而,使用通用 LLM 模型作为 GUI Agent 会面临几个挑战:1)可靠地识别用户界面中的可交互图标;2)理解屏幕截图中各种元素的语义并准确地将预期操作与屏幕上的相应区域关联起来。
OmniParser 通过将 UI 屏幕截图从像素空间“分词”为可由 LLMs 解析的结构化元素来弥补这一差距。这使得 LLMs 能够在一组解析后的可交互元素的基础上进行基于检索的下一步操作预测。
OmniParser V2 将这一能力提升到了一个新的水平。与它的前一个版本相比,它在检测更小的可交互元素方面实现了更高的准确性,并且推理速度更快,使其成为 GUI 自动化的一个有用工具。
特别是,OmniParser V2 通过使用更大的可交互元素检测数据集和图标功能描述数据集进行了训练。通过减少图标描述模型的图像大小,让 OmniParser V2 的延迟比前一版本降低了 60%。
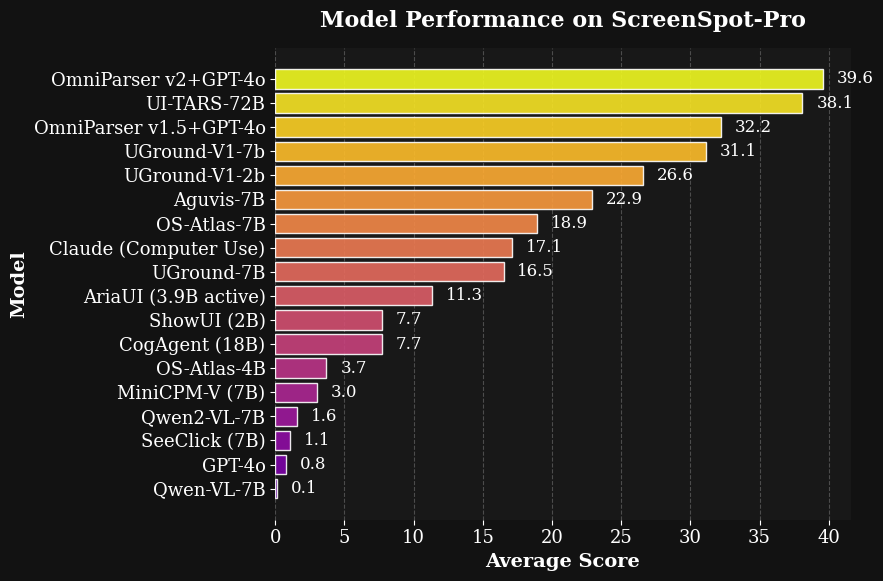
值得注意的是,Omniparser+GPT-4o 在最近发布的高分辨率屏幕和小型目标图标特征的 grounding 基准 ScreenSpot Pro 中实现了最先进的平均准确率 39.6,这比 GPT-4o 原始得分 0.8 有了显著提升。
详情查看发布公告。
更新")





还没有评论,来说两句吧...