

100+ 重磅嘉宾出席 GOTC 2024! 499 专业观众票 【限时免费】


Apache SeaTunnel 2.3.6 版本于近日正式发布,社区期待的 SeaTunnel Zeta Master/Worker 新架构、事件通知机制、支持动态编译的transform等新功能和新能力在这次版本中都有了全面的更新,并添加了首个向量数据库 Milvus。此外,本版本还进行了一些基础性的 Bug 修复和文档修复等,欢迎尝试使用!
📥 2.3.6 版本下载:https://seatunnel.apache.org/download/
📖 Release Note:https://github.com/apache/seatunnel/blob/2.3.6/release-note.md
重点更新
SeaTunnel Zeta Master/Worker 新架构
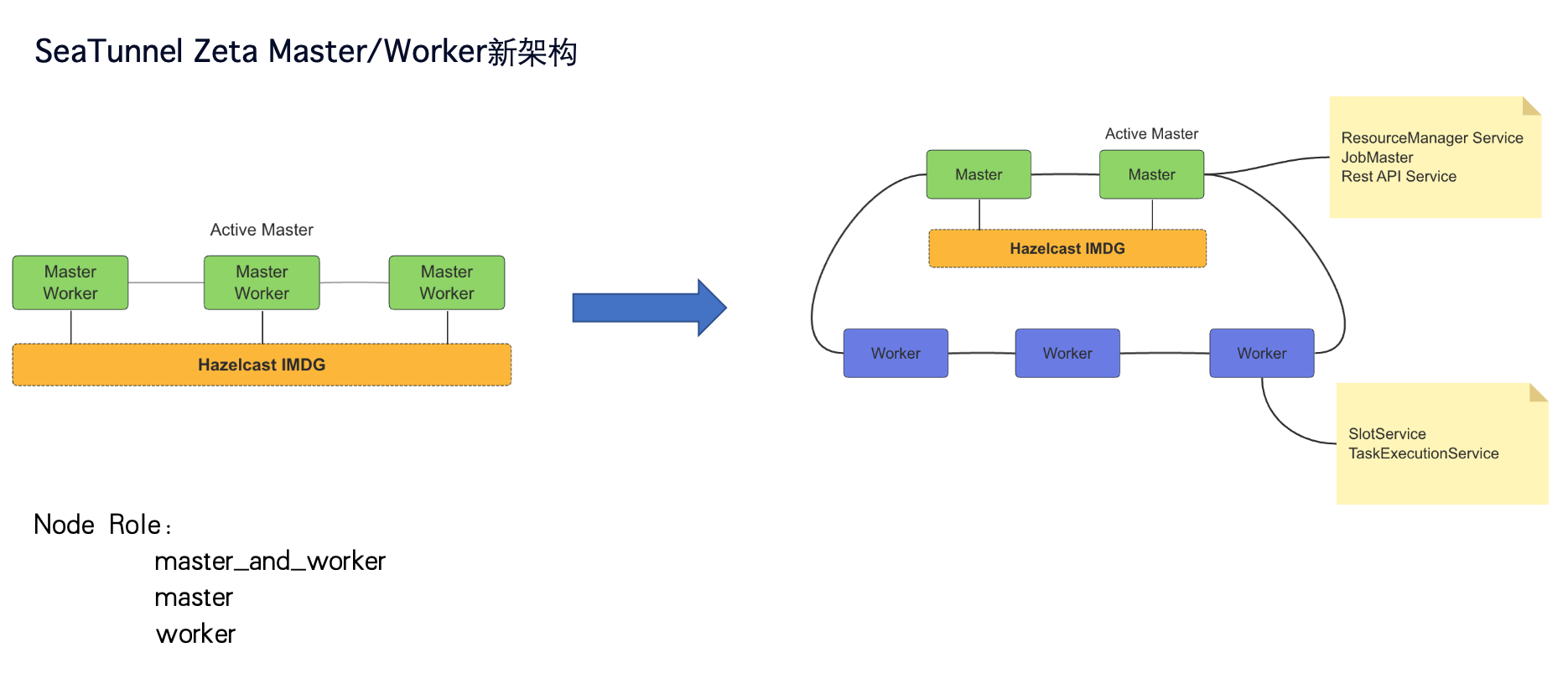
首先是实现 SeaTunnel Zeta Master/Work 新架构。在 SeaTunnel 当前的架构里是不分 Master 和 Worker 角色的,所有节点既是 Master 又是 Worker、SeaTunnel会从这些Master节点中选择一个节点,将其作为 active 的 Master 节点,其他 Master 节点作为 standby 节点。下面是 SeaTunnel 集群的分布式内存网格,就是在各个节点之间可以向 HashMap 里导入数据,HashMap 就会分散在集群的所有节点中,并有副本。Flink 等工具会把任务的状态信息存在 Zk 等三方系统中。
而 SeaTunnel Zeta 不需要三方系统,其内部自带的分布式内存网格就可以存储作业的状态信息。任何节点进程异常退出,都会去重新分布内存网格里面的数据,保证作业在另外的节点去进行容错恢复时能够找到之前的状态。这样的架构存在一个问题,当 Master/Worker 在一起的时候,一旦集群的负载比较高,假设一个 active Master 的节点进程异常退出,它会容错在新的节点上,在容错的过程中,因为 Master 节点进程异常退出,所有的任务都要重新进行容错,这就可能导致新的 Master 节点上的 Worker 节点高负载,这可能又会使新的 Master 进程异常退出。
为了解决这个问题,我们开发了新的架构,将 Master 和 Worker 分开部署,Master 上只存储数据和调度任务,Work 节点只进行任务的执行和资源的提供。这样整个 SeaTunnel 中节点的角色就分为 Master、Worker,master_and_worker 三种,用户可以根据需求去使用。
支持使用SQL的方式创建SeaTunnel任务
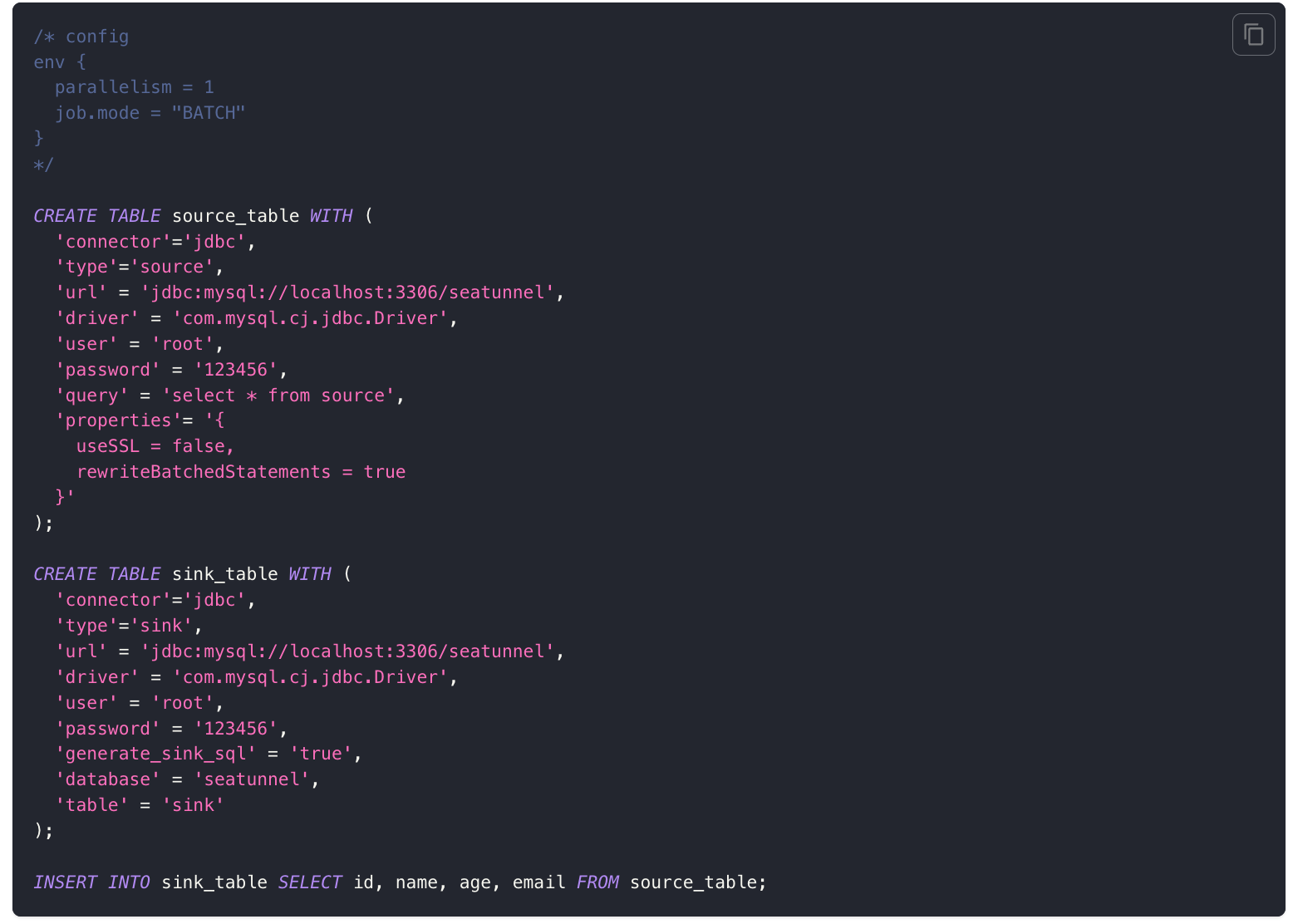
第二个是支持使用 SQL 的方式去创建 SeaTunnel 任务。之前 SeaTunnel 的任务创建是使用 HOCON 的文件格式,而 2.3.6 版本支持使用 SQL 的方式创建任务。用户可以 创建一张 Source 表,一张 Sink 表,最终通过 insert into 语句,从 Source 表里面查数据,同步到目标表。
Zeta CDC同步释放空闲的Reader
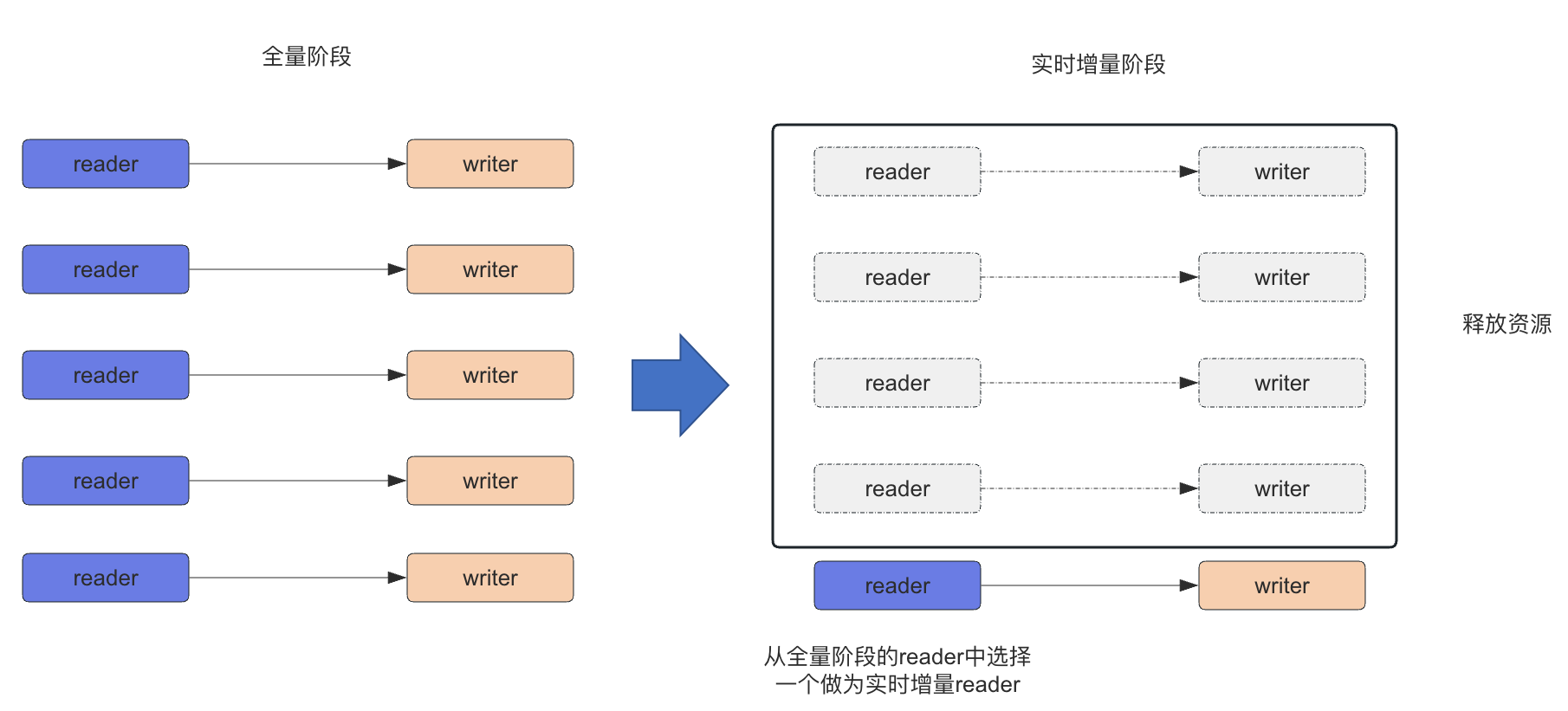
第三个是新增了 Zeta CDC 同步释放空闲 Reader 的功能。在 CDC 全量阶段,为了加快同步的速度,会并行地开很多 Reader 进行数据的读取和写入。但是当进入到解析 binlog 进行增量同步的阶段,读取只能是单线程的,因为 binlog 是有序的,不能把顺序打乱。此时,前面的四个 Reader 和 Writer 其实就没有任何的数据流了。在 2.3.6 版本中,Apache SeaTunnel 会释放之前的资源,把里面的 JDBC 资源、内存的资源等全部释放,保证尽量占用更少的空间同步更多的数据,支持更大规模任务的运行。针对单个 Writer 写入较慢的问题,可以在 Writer 里设置 Writer 的线程数。这样,读是单线程,而写又是多线程并行的写入。因为读文件解析速度较快,单个作业能够达到每秒三十多兆的写入速度。如果写入遇到困难,Writer 端也支持设置并行度。
支持事件通知机制

支持事件通知机制,通过这些 API,可以将 Zeta 引擎里面产生的事件,比如作业成功或失败,或者 DDL 变更信息通过请求发送到其他的系统中去。
添加向量数据库Milvus支持
向量数据库可加速 AI 应用程序的开发,并简化由人工智能驱动的应用程序工作负载的运作,已成为大模型时代的得力助手。为更好地支持 AI 开发,Apache SeaTunnel 2.3.6 版本添加了对向量数据库 Milvus 的支持。这是 Apache SeaTunnel 支持的首个向量数据库,后续将扩展对其他向量数据库的支持。
支持动态编译的transform
Apache SeaTunnel 2.3.6 版本提供一种可编程的方式来处理行,允许用户根据现有行字段作为参数自定义任何业务行为,甚至基于现有行字段作为参数的RPC请求,或者通过从其他数据源检索相关数据来扩展字段。为了区分业务,用户还可以定义多个转换来进行组合,更加高效和灵活地适配业务场景。
详情请查看https://seatunnel.apache.org/docs/2.3.6/transform-v2/dynamic-compile
资源隔离
通过对任务节点添加tag标签的方式来进行集群资源的区分,帮助用户更加合理地规划集群任务的调度。
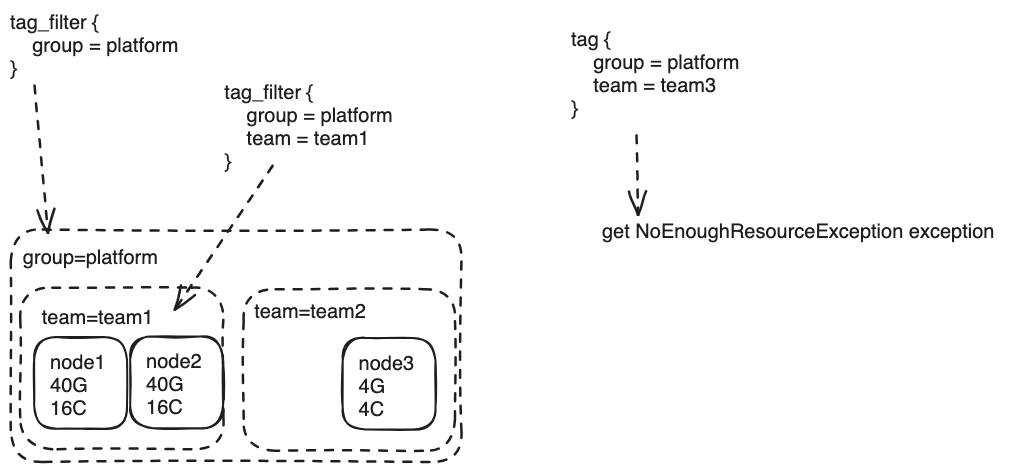
资源隔离示意图
关于资源隔离详情和实现方法请查看 https://seatunnel.apache.org/docs/2.3.6/seatunnel-engine/resource-isolation
Sink统一支持table/database等通配符使用
新版本还提供了一个接收选项通配符功能, 通过通配符可以获取上游表格元数据。当用户需要动态获取上游表格元数据(例如多表写入)时,这个功能非常重要,可以帮用户更加方便和统一地实现多表配置方式,降低多表配置的难度。
查看文档了解如何使用此功能:https://seatunnel.apache.org/docs/2.3.6/concept/sink-options-placeholders
其他
此外,Apache SeaTunnel 2.3.6 版本还实现了 Spark/Flink引擎下的用户自定义参数功能,新增 Hudi Sink 等多个 Connector 支持,Transform 和 Zeta Engine也进行了众多更新,并修复了文档遗留问题。
详情可查看Release Note: https://github.com/apache/seatunnel/blob/2.3.6/release-note.md
致谢
感谢@Hisoka-X主导本次发版工作,感谢以下贡献者对本次发版的支持(排名不分先后):
Assert, Asura7969, Carl-Zhou-CN, ChunFuWu, Coen, CosmosNi, Dongyeon Lee, Eric, Felix, Feng Ruohang, FuYouJ, Guangdong Liu, JackeyLee007, Jarvis, Jast, Jia Fan, Kim, Leon Yoah, Marvin, THZ, TaoZex, TeAmo, Thomas-HuWei, Tyrantlucifer, Wenjun Ruan, Wudadada, XiaoMaYi, Xiaojian Sun, Xuzz, YalikWang, ZhiLin Li, Zhihong Pan, ZhilinLi, bingquanzhao, corgy-w, dailai, fcb-xiaobo, gitfortian, hailin0, halo.kim, hawk9821, hilo, ic4y, latch890727, lightzhao, litiliu, lizhenglei, ponxu, rtyuy, seckiller, tcodehuber, useheart, xiaochen, zhangdonghao, zhiwei liu, zuo, 老王, 不忘初心, 狂野之驴







还没有评论,来说两句吧...